Internet
Sources:
- https://cs.fyi/guide/how-does-internet-work
- https://www.vox.com/2014/6/16/18076282/the-internet
- https://web.stanford.edu/class/msande91si/www-spr04/readings/week1/InternetWhitepaper.htm
- https://www.youtube.com/watch?v=KEWe-5Bk3Q0&ab_channel=LaurenDagworthy
How does the Internet Work?
**Network - group of computers or other devices which are connected to each other The internet is a network of networks
The core of the internet is a global network of interconnected routers, which are responsible for directing traffic between different devices and systems. When you send data over the internet, it is broken up into small packets that are sent from your device to a router. The router examines the packet and forwards it to the next router in the path towards its destination. This process continues until the packet reaches its final destination.
To ensure that packets are sent and received correctly, the internet uses a variety of protocols:
- including the Internet Protocol (IP) and the Transmission Control Protocol (TCP).
- IP is responsible for routing packets to their correct destination
- TCP ensures that packets are transmitted reliably and in the correct order.
Technologies and protocol to note:
- Domain Name System (DNS)
- Hypertext Transfer Protocol (HTTP)
- Secure Sockets Layer/Transport Layer security (SSL/TLS)
**Basic Concepts and Terminology
- Packet: a small unit of data that is transmitted over the internet
- Router: a device that directs packets of data between different networks
- IP Address: a unique id assigned to each device on a network, used to route data to the correct destination
- Domain Name: A human readable name that is used to identify a website
- DNS: domain name system that translates domain names to IP addresses
- HTTP: hypertext transfer protocol used to transfer data between a client and a server
- HTTPS: an encrypted version of HTTP to provide secure communication between a client and server
- SSL/TLS: The secure sockets layer and transport layer security protocols are used to provide secure communication over the internet
The Role of Protocols in Internet
Protocols play a critical role in enabling communication and data exchange over the internet. A protocol is a set of rules and standards that define how information is exchanged between devices and systems.
- IP: responsible for routing packets of data to their correct destination
- TCP and UDP: ensure that packets are transmitted reliably and efficiently
- DNS: used to translate domain names into IP addresses
- HTTP: used to transfer data between clients and servers
The key benefit here of using standardized protocols is that they allow devices and systems from different manufacturers and vendors to communicate with each other seamlessly
Understanding IP Addresses and Domain Names
IP addresses are typically represented as a series of four numbers separated by periods, such as “192.168.1.1”. Domain names are human-readable like “google.com” and they are translated into IP addresses using DNS.
When you enter a domain name name into your web browser, your computer sends a DNS query to a DNS server, which returns the corresponding IP address. Your computer then uses that IP address to connect to the website or other resource you’ve requested.
IPv6 allows for a mind boggling number of unique addresses
Introduction to HTTP and HTTPS
When you visit a website, your web browser sends an HTTP request to the server, asking for the webpage or other resource you’ve requested. The server then sends an HTTP response back to the client, containing the requested data.
HTTPS is a more secure version that uses SSL/TLS encryption, which helps protect sensitive information such as login credentials, payment information, and other personal data.
Building Applications with TCP/IP
**Key Concepts:
- Ports: identify the application or service running on a device. Each app or service is assigned to a unique port number, allowing data to be sent to the correct destination
- Sockets: a socket is a combination of an IP address and a port number, representing a specific endpoint for communication. They are used to establish connections between devices and transfer data between apps.
- Connections: A connection is established between two sockets when two devices want to communicate with each other.
- Data Transfer: Once a connection is established, data can be transferred between the apps running on each device. Data is transmitted in segments, with each segment containing a sequence number and other metadata
TCP is responsible for routing application protocols to the correct application on the destination computer.
TCP works like this:
- When the TCP layer receives the application layer protocol data from above, it segments it into manageable ‘chunks’ and then adds a TCP header with specific TCP information to each ‘chunk’. The information contained in the TCP header includes the port number of the application the data needs to be sent to.
- When the TCP layer receives a packet from the IP layer below it, the TCP layer strips the TCP header data from the packet, does some data reconstruction if necessary, and then sends the data to the correct application using the port number taken from the TCP header.
This is because TCP doesn’t know anything about IP addresses. TCP’s job is to get application level data from application to application reliably. The task of getting data from computer to computer is the job of IP.
Unlike TCP, IP is an unreliable, connectionless protocol. IP doesn’t care whether a packet gets to it’s destination or not. Nor does IP know about connections and port numbers. IP’s job is too send and route packets to other computers. IP packets are independent entities and may arrive out of order or not at all. It is TCP’s job to make sure packets arrive and are in the correct order. About the only thing IP has in common with TCP is the way it receives data and adds its own IP header information to the TCP data.
Securing Internet Communication with SSL/TLS
**Key Concepts:
- Certificates: SSL/TLS certificates are used to establish trust between the client and server. They contain information about the identity of the server and are signed by a trusted third party to verify their authenticity
- Handshake: during the SSL/TLS handshake process, the client and server exchange information to negotiate the encryption algorithm and other parameters for the secure connection
- Encryption: once the secure connection is established, the data is encrypted using the agreed upon algorithm and can be transmitted securely between the client and server
If we were to follow the path that the message “Hello computer 5.6.7.8!” took from our computer to the computer with IP address 5.6.7.8, it would happen something like this:
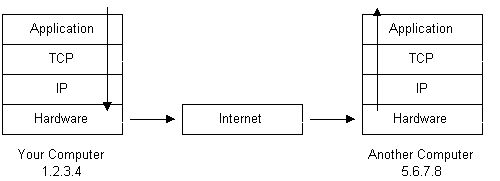
- The message would start at the top of the protocol stack on your computer and work it’s way downward.
- If the message to be sent is long, each stack layer that the message passes through may break the message up into smaller chunks of data. This is because data sent over the Internet (and most computer networks) are sent in manageable chunks. On the Internet, these chunks of data are known as packets.
- The packets would go through the Application Layer and continue to the TCP layer. Each packet is assigned a port number. Ports will be explained later, but suffice to say that many programs may be using the TCP/IP stack and sending messages. We need to know which program on the destination computer needs to receive the message because it will be listening on a specific port.
- After going through the TCP layer, the packets proceed to the IP layer. This is where each packet receives it’s destination address, 5.6.7.8.
- Now that our message packets have a port number and an IP address, they are ready to be sent over the Internet. The hardware layer takes care of turning our packets containing the alphabetic text of our message into electronic signals and transmitting them over the phone line.
- On the other end of the phone line your ISP has a direct connection to the Internet. The ISPs router examines the destination address in each packet and determines where to send it. Often, the packet’s next stop is another router. More on routers and Internet infrastructure later.
- Eventually, the packets reach computer 5.6.7.8. Here, the packets start at the bottom of the destination computer’s TCP/IP stack and work upwards.
- As the packets go upwards through the stack, all routing data that the sending computer’s stack added (such as IP address and port number) is stripped from the packets.
- When the data reaches the top of the stack, the packets have been re-assembled into their original form, “Hello computer 5.6.7.8!”
What is HTTP
Sources:
- https://cs.fyi/guide/http-in-depth
- https://www.cloudflare.com/en-gb/learning/ddos/glossary/hypertext-transfer-protocol-http/
- https://www.youtube.com/watch?v=j9QmMEWmcfo&ab_channel=ByteByteGo
HTTP is a TCP/IP based app communication protocol that standardizes how clients and servers communicate with each other. It defines how content is requested and transmitted across the internet.
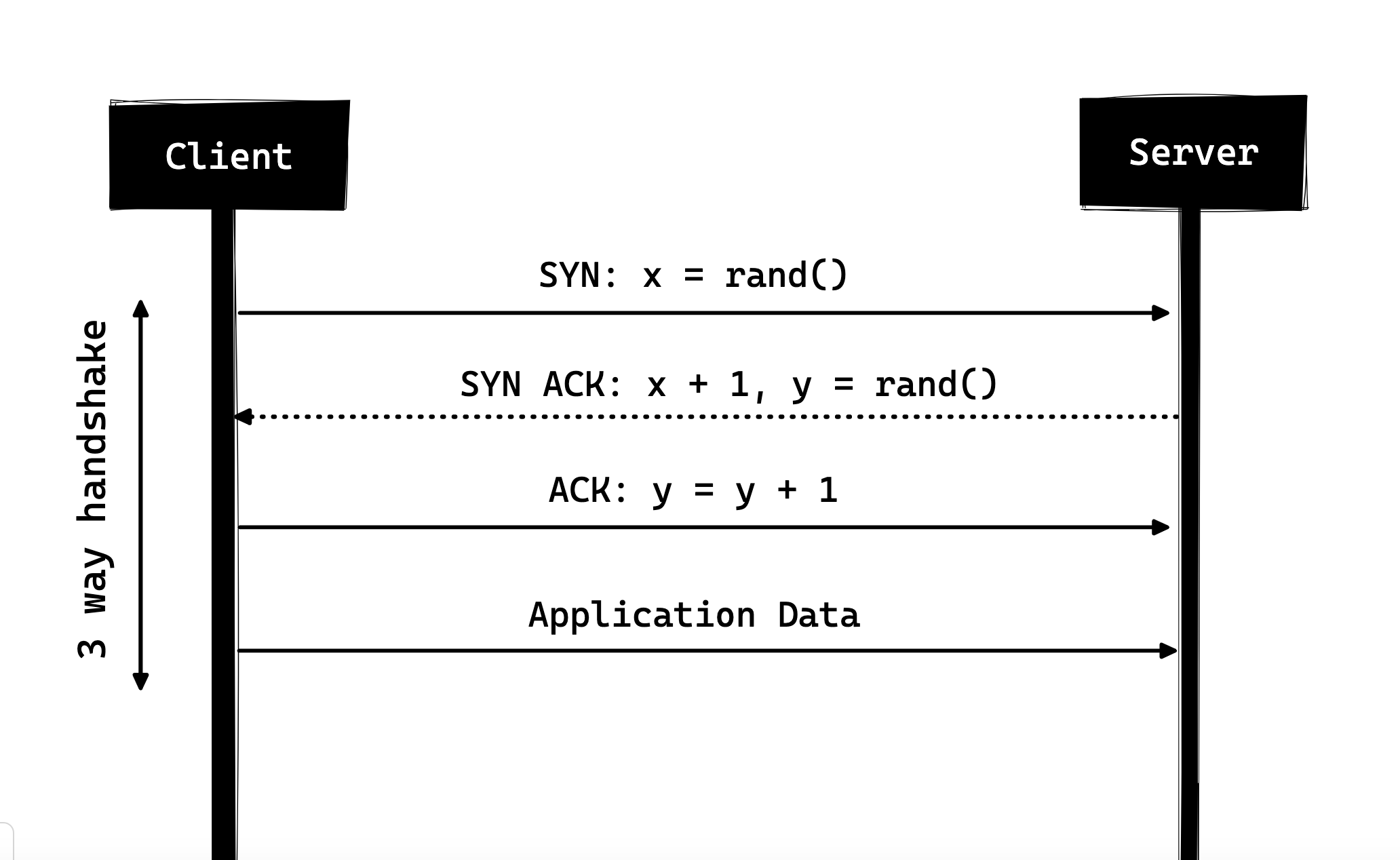
**Three Way Handshake
Client and server share a series of packets before starting to share the application data.
- SYN - Client picks up a random number, let’s say x, and sends it to the server.
- SYN ACK - Server acknowledges the request by sending an ACK packet back to the client which is made up of a random number, let’s say y picked up by server and the number x+1 where x is the number that was sent by the client
- ACK - Client increments the number y received from the server and sends an ACK packet back with the number y+1 Once the three-way handshake is complete, the data sharing between the client and server may began.
HTTP is a stateless protocol meaning that the server doesn’t maintain the information about the client and so each request needs to have all information necessary to fulfill the request.
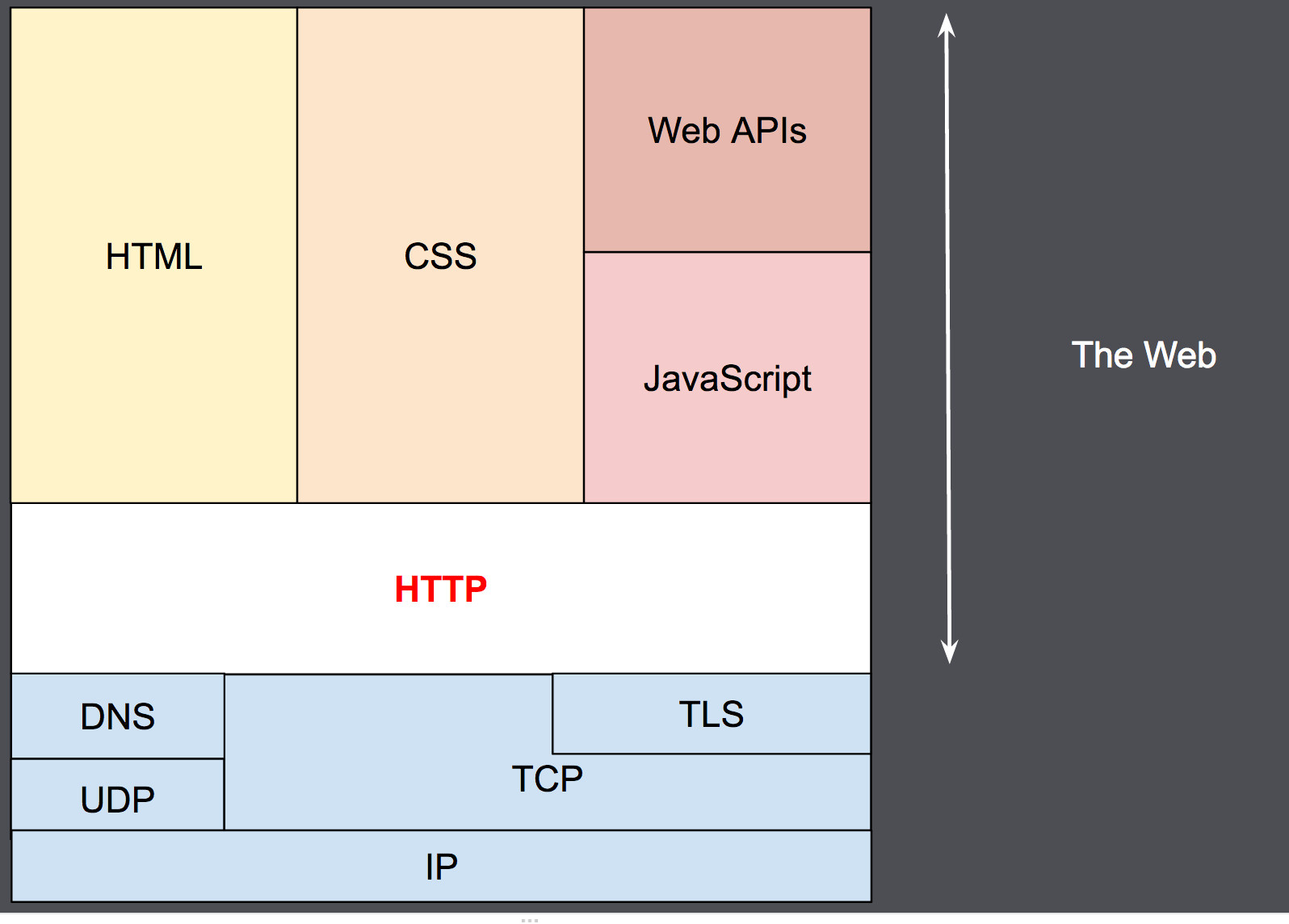
Client: the user-agent
The browser is always the entity initiating the request. It is never the server. To display a web page, the browser sends an original request to fetch the HTML document that represents the page.
The Web server
The server serves the document as requested by the client. A server may appear as only a single machine virtually; but it may actually be a collection of servers sharing the load (load balancing) or other software (such as caches, a db server, or e-commerce servers)
Between the Web browser and the server, numerous computers and machines relay the HTTP messages. Due to the layered structure of the Web stack, most of these operate at the transport, network or physical levels, becoming transparent at the HTTP layer and potentially having a significant impact on performance. Those operating at the application layers are generally called proxies. These can be transparent, forwarding on the requests they receive without altering them in any way, or non-transparent, in which case they will change the request in some way before passing it along to the server. Proxies may perform numerous functions:
- caching (the cache can be public or private, like the browser cache)
- filtering (like an antivirus scan or parental controls)
- load balancing (to allow multiple servers to serve different requests)
- authentication (to control access to different resources)
- logging (allowing the storage of historical information)
Basic aspects of HTTP
- HTTP is simple
- HTTP is extensible
- HTTP is stateless but not sessionless
- HTTP cookies allow HTTP requests to share the same context or the same state
What can be controlled by HTTP
- Caching
- authentication
- proxing
- sessions
HTTP flow
- Open a TCP connection: The TCP connection is used to send a request, or several, and receive an answer. The client may open a new connection, reuse an existing connection, or open several TCP connections to the servers
- Send an HTTP message: HTTP messages (before HTTP/2) are human-readable. With HTTP/2, these simple messages are encapsulated in frames, making them impossible to read directly, but the principle remains the same. For example:
GET / HTTP/1.1
Host: developer.mozilla.org
Accept-Language: fr
- Read the response sent by the server
HTTP/1.1 200 OK
Date: Sat, 09 Oct 2010 14:28:02 GMT
Server: Apache
Last-Modified: Tue, 01 Dec 2009 20:18:22 GMT
ETag: "51142bc1-7449-479b075b2891b"
Accept-Ranges: bytes
Content-Length: 29769
Content-Type: text/html
- close or reuse the connection for further requests
HTTP status codes
- 1xx: informational, request received/processing
- 2xx: success, successfully received, understood and accepted
- 3xx: redirect, further action must be taken/redirect
- 4xx: client error, request does not have what it needs
- 5xx: server error, sever failed to fulfill an apparent request
Browsers
Sources:
- https://web.dev/articles/howbrowserswork
- https://developer.mozilla.org/en-US/docs/Web/Performance/How_browsers_work
How Browsers Work
The browser’s main components:
- the user interface
- the browser engine
- the rendering engine
- Parsing HTML to construct the DOM tree
- Render tree construction. This tree includes both the styling information as well as the visual instructions that define the order in which the elements will be displayed
- Layout of the render tree. This is the entire process of calculating values for evaluating the desired position is called a layout process. Every node is assigned exact coordinates.
- Painting the render tree
- networking
- UI backend
- JavaScript interpreter
- Data storage
Parsing a document means translating it to a structure the code can use.
**Parser - Lexer Combination
- Lexical analysis: process of breaking the input into tokens
- Syntax analysis: applying of the language syntax rules
DOM is short for Document Object model. It is the object representation of the HTML document and the interface of HTML elements to the outside world like JavaScript.
DNS and how it works?
Sources:
-
DNS is the phonebook of the internet
-
DNS converts a hostname into a computer friendly IP address
-
Each device connected to the internet has a unique IP address which other machines use to find the device
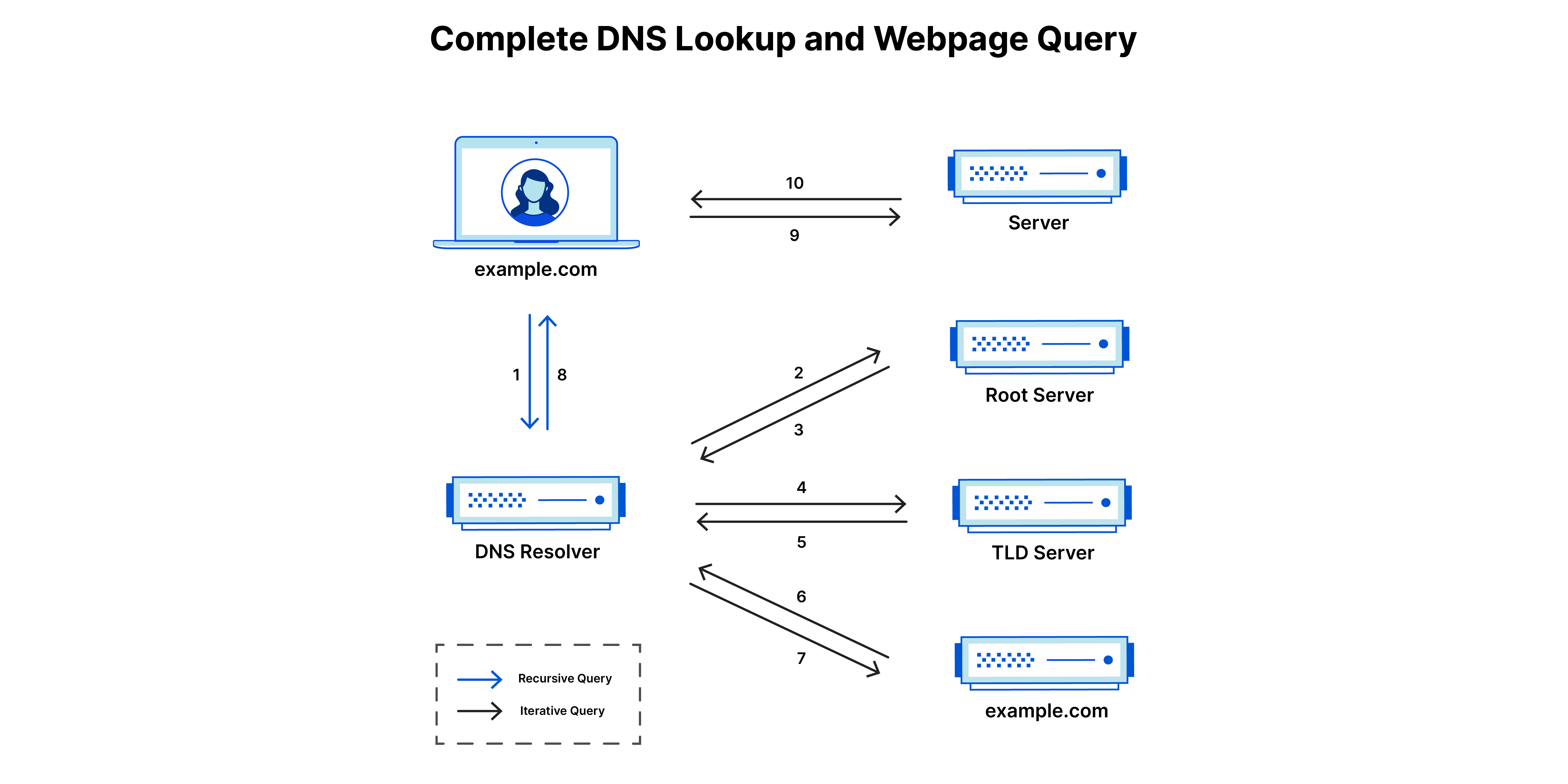
There are 4 DNS servers involved in loading a webpage
- DNS recursor: think librarian who is asked to find book somewhere in the library. It is a server that receives queries from client machines. Then it makes additional requests to satisfy client’s DNS query
- Root nameserver: think index in a library that points to a rack of books. It is the first step in translating human readable host names into IP addresses
- TLD nameserver: think specific rack of books. This is the top level domain server. It is the next step in the search for a specific IP address and it hosts the last position of a hostname (like com)
- Authoritative nameserver: think dictionary on a rack of books. A specific name can be translated into a definition. If the ANS has access to the requested record, it will return the IP address for the requested hostname back to the DNS Recursor that made the initial request
What is DNS caching? Where does DNS caching occur?
The purpose of caching is to temporarily store data in a location that results in improvements in performance and reliability for data requests. Useful so that DNS queries can be resolved earlier and additional queries further down the DNS lookup chain can be avoided, thereby improving load times and reducing bandwidth/CPU consumption.
Modern web browsers are designed by default to cache DNS records for a set amount of time.
What is a Domain Name?
Sources:
- https://developer.mozilla.org/en-US/docs/Learn/Common_questions/Web_mechanics/What_is_a_domain_name
- https://www.cloudflare.com/en-gb/learning/dns/glossary/what-is-a-domain-name/
**Structure of domain names:
- TLD (top level domain) - tell users the general purpose of the service behind the domain name. The most generic TLDs are .com, .org, .net
- Labels - follow TLD, it is a case insensitive character sequence
You CANNOT buy a domain name. The difference between a domain and a URL is than a IRL contains the domain name of a site as well as other information including the protocol and the path.
What is hosting?
Sources:
- https://www.youtube.com/watch?v=htbY9-yggB0&ab_channel=Pickaweb.co.uk
- https://www.youtube.com/watch?v=Kx_1NYYJS7Q&ab_channel=BenAwad
- https://developer.mozilla.org/en-US/docs/Learn/Common_questions/Web_mechanics/Pages_sites_servers_and_search_engines
What is the difference between webpage, website, web sever, and search engine?
Webpage: simple document displayable by a browser Website: collection of linked web pages that share a unique domain name Web Server: a computer hosting one or more websites Search engine: special kind of website that helps users find web pages from other websites
What is a web server?
It can refer to hardware or software or both of them working together. On the hardware side, a web server is a computer that stores web server software and a website’s component files. It connects to the internet and supports physical data interchange. On the server side, a web server includes several parts that control how web users access hosted files.
At the most basic level, whenever a browser needs a file that is hosted on a web server, the browser requests the file via HTTP. When the request reaches the correct (hardware) web server, the (software) HTTP server accepts the request, finds the requested document, and sends it back to the browser, also through HTTP. (If the server doesn’t find the requested document, it returns a 404 response instead.)
A static web server, or stack, consists of a computer (hardware) with an HTTP server (software). We call it “static” because the server sends its hosted files as-is to your browser.
A dynamic web server consists of a static web server plus extra software, most commonly an application server and a database. We call it “dynamic” because the application server updates the hosted files before sending content to your browser via the HTTP server.